Researchers



Dataset consists of 200 traffic sign categories captured in Slovenian roads spanning in around 7000 high-resolution images. Images were provided and annotated by a Slovenian company DFG Consulting d.o.o. The RGB images were acquired with a camera mounted on a vehicle that was driven through six different Slovenian municipalities. The image data was acquired in rural as well as urban areas. Only images containing at least one traffic sign were selected from the vast corpus of collected data. Moreover, the selection was performed in such a way that there is usually a significant scene change between any pair of selected consecutive images.

The evaluation dataset termed DFG Traffic Sign Dataset was created by focusing only on a planar traffic signs with a sufficient number of samples available. Each category has at least 20 instances. Samples with the bounding box size of at least 30 pixels are tightly annotated, while samples with the bounding box size above 15 pixels but below 30 pixels are flagged as difficult and ignored in the training/evaluation. This yielded a dataset with:
- 5254 training images and 1703 testing images
- 6758 images with 1920x1080 resolution
- 199 images with 720x576 resolution
- The images have been anonymized by blurring the faces and vehicle license plates to comply with the EU GDPR legislation.
- 13239 tightly annotated (polygon) traffic sign instances larger than 30 px
- 4359 loosely annotated (bounding box) traffic sign instances smaller than 30 px marked as ignore
- 200 traffic sign categories with at least 20 instances per category
- roughly 70% of categories with a low appearance changes and 30% with a large appearance variability
Augmentation Dataset
Additional augmentation dataset was created by inserting cropped instances of traffic signs into Belgium Traffic Sign Dataset. Existing traffic signs (non-difficult) are normalized based on tight annotation and then artificially distorted in:
- geometry/shape (perspective change, changes in scale)
- appearance (variations in brightness and contrast)
The augmentation dataset consists of:
- over 30000 additional annotation instances
- additional 8775 images
- each traffic sign category is ensured to have 200 instances
License and citation
The dataset is licensed under Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License. For comerical use please contact Danijel Skočaj.

Please cite our paper published in the IEEE Transactions on Intelligent Transportation Systems journal when using this dataset:
@article{Tabernik2019ITS,
author = {Tabernik, Domen and Sko{\v{c}}aj, Danijel},
journal = {IEEE Transactions on Intelligent Transportation Systems},
title = {{Deep Learning for Large-Scale Traffic-Sign Detection and Recognition}},
year = {2019},
doi={10.1109/TITS.2019.2913588},
ISSN={1524-9050}
}
DOWNLOAD:
- Annotations are provided in COCO json format compatible with Detectron/Mask-RCNN:
- Default annotations (for ~7000 images): DFG-tsd-annot-json.zip
- Annotation with augmented images (for ~7000 original + ~8700 augmented images): DFG-tsd-aug-annot-json.zip
- Annotations for training set with small instances (less than 30px) marked as ‘ignore’ DFG-tsd-aug-annot-json-with-difficult-samples.zip
- Original and augmented images: JPEGImages.tar.bz2
- Category information: DFG-tsd-category-info.tar.bz2
Revision changes
- v1.02 (14.06.2019): Updated segmentation/mask annotations (fixed Y coordinate and added masks for augmentation data by converting bounding box to polygon)
- v1.01 (25.04.2019): Fixed annotation for image 0004024.jpg (changed III-84 to III-85.1)
Results and code download
CODE DOWNLOAD: Code with our improvements to the Mask R-CNN as used in our evaluation is also available in a forked Detectron framework on GitHub repository.
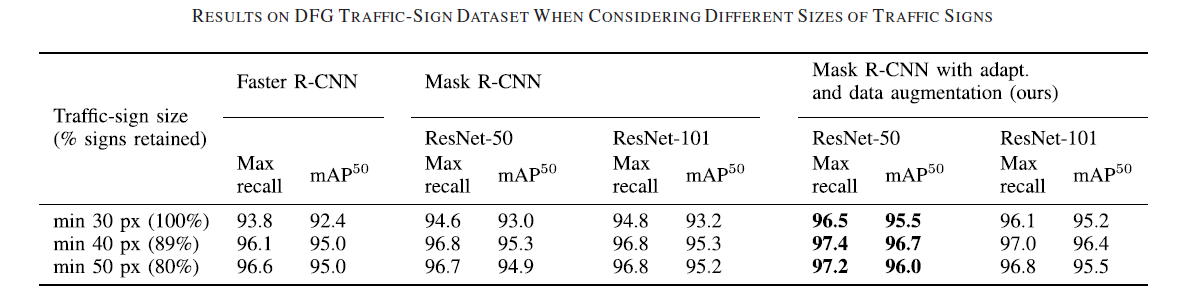
See our Research of the Traffic-Sign Detection for Inventory Management page for more details on the results using our proposed modifications for the Mask R-CNN model.