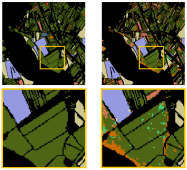
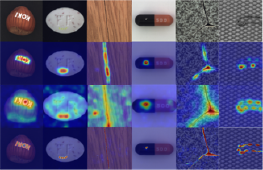
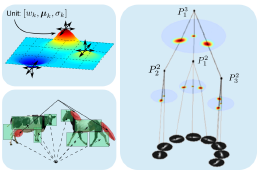
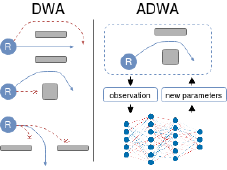
Research topics Visual object tracking Contains 7 subtopics We have a long tradition in visual object tracking research. The primary goal is developing method for object localization, where the single training image is provided in the first frame. In addition to designing new algorithms for object tracking, we have invested significant effort also in development of performance evaluation measures and protocols for objective tracker evaluation. Geophysics deep learning models Contains 2 subtopics The reseach is dedicated to geophysics reconstruction and forecast problems such as sea-surface temperature reconstruction and coastal flood prediction models. Some of our models are already used by national weather agencies, including European Centre for Medium-Range Weather Forecasts (ECMWF). Object counting Contains 3 subtopics We are designing novel deep architectures for object counting based on trainable category-specific detectors and low-shot counters. Surface defect detection Contains 2 subtopics We are designing novel deep architectures for visual surface inspection. The developed methods allow specialization for large defect detection such as cracks, as well as smooth deformations on reflective surfaces like dents. The methods are learning-based and are thus robust, run realtime and are applicable to a wide range of real problems. Several of the methods are part of most advances surface inspection commercial systems. Remote sensing Remote sensing involves scanning of the earth by satellite or high-flying aircraft and analyzing it. Since the amount of data acquired this way is huge and growing, matchine learning can be used to perform tasks efficently. We are using modern computer vision methods and apply them to different problems in remote sensing. Visual anomaly detection This research focuses on the development of unsupervised visual anomaly detection methods. Trained on anomaly-free samples only, these methods attempt to remove the need for a difficult acquisition of a diverse set of anomalous objects while aiming to match the performance of supervised methods. Vision for robotic manipulation Developing novel vision-based methods for robotic manipulation, with a focus on grasping deformable objects such as cloths, towels, and garments. Introducing CeDiRNet-3DoF and the ViCoS Towel Dataset for benchmarking and advancing cloth manipulation in robotics. Deep structured models Contains 4 subtopics This research is dedicated to deep models which utilize compositional structure of object parts. The methodologies span from modern deep learning frameworks to more classical hierarchies of parts. Autonomous boats perception methods Unmnanned surface vehicles (USV) are robotic boats that can be used for coastal patrolling in a numerous applications ranging from surveillance to water cleanness control. We are developing computer vision algorithms that enable autonomous operation in the highly dynamic environments in which the USVs are applied. Deep reinforcement learning for navigation This research investigates the development of autonomous mobile robot navigation methods using deep reinforcement learning. Our methods aim to produce navigation policies which are learned completely in simulation and deployed on real robots. Traffic-sign detection We explore automation of traffic-sign inventory management using deep-learning models. Models such as Faster R-CNN and Mask R-CNN are improved and applied to traffic sign detection. Instead of specializing in automated detection for only several traffic sign categories we explore possibility of automating the detection of over 200 different traffic signs that are needed to automate the traffic-sign inventory management. Interactive learning Contains 3 subtopics The laboratory was involved in several EU projects on the topic of interactive robot learning, ranging from self-supervised learning of object affordances to interactive learning in a dialogue with a tutor. We have been also developing methods for interactive learning on different levels of interaction. Online learning with mixture models Contains 3 subtopics Online learning from data streams is a challenging problem in which datapoints arrive in continual fashion and cannot be stored, but rather compressed into a model. We have explored this problem in the context of learning by mixture models. We developed several algorithms that build mixture models in under generative or discriminative constraints and introduced a concept of unlearning into the mixure models. Robot place mapping & recognition Contains 4 subtopics We developed algorithms for place mapping and recognition by mobile robots. The methods are image-based as well as by using laser range scanners and span hierarchical, deep learning and traditional subspace methods. Camera focus measures We proposed an efficient measure of camera focus. The measure analyzes the image frequency content using a DCT to extract the the image spectrum and evaluates a Bayes entropy of the spectrum to measure the focus. Subspace methods for visual learning and recognition One of our main research topics in the past were subspace methods. We have proposed several methods for robust estimation of subspace coefficients and for learning subspace representations for both the reconstructive (PCA), and the discriminative methods (LDA,CCA). By combining the properties of these methods we were able to extend the standard approaches into incremental and robust ones, and to show the efficiency of the proposed methods in many mostly computer vision tasks. Educational robotics We have used, evaluated and even developed several robotic systems that are used in our teaching activities. We are developing an open-source robot manipulator platform and a low-cost manipulator that the system runs on.