Researchers



Introduction
One of the main research topics of our group in the past were subspace methods. We have proposed several methods for robust estimation of subspace coefficients and for learning subspace representations. We have considered both types of subspace methods: the reconstructive methods (Principal components analysis), and the discriminative methods (Linear Discriminant Analysis, Canonical Correlation Analysis). By combining the properties of these methods we were able to extend the standard approaches into incremental and robust ones, and to show the efficiency of the proposed methods in many mostly computer vision tasks.
Robust estimation of subspace coefficients
Linear subspace methods that provide sufficient reconstruction of the data such as PCA offer an efficient way of dealing with missing pixels, outliers, and occlusions that often appear in the visual data. Discriminative methods, such as LDA and CCA, which on the other hand, are better suited for classification and regression tasks, are highly sensitive to corrupted data. We present a theoretical framework for achieving best of both types of methods: an approach that combines the discrimination power of discriminative methods with the reconstruction property of reconstructive methods which enables one to work on subsets of pixels in images, to efficiently detect and reject the outliers.
The principle is demonstrated in the figure below. Column (a) depicts a test image, which is significantly occluded or different than images in the test set (column (i)). The robust procedure selects only the pixels depicted in the column (g) to be used for the estimation of the subspace coefficients, which results in a very good reconstruction (column (h)).

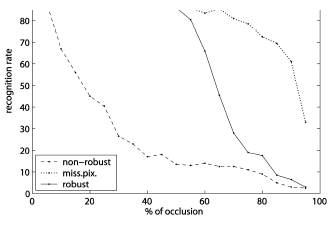
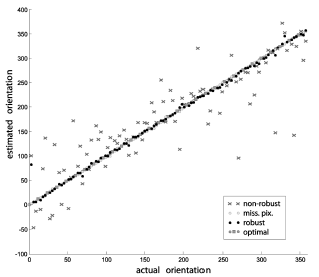
The proposed approach is therefore capable of robust classification/regression with a high-breakdown point. The theoretical results are demonstrated on several computer vision tasks showing that the proposed approach significantly outperforms the standard discriminative methods in the case of missing pixels and images containing occlusions and outliers. The figures below show the results of experiments, where robust LDA was used for face recognition, and CCA was used for estimation of rotation.
RobCoeff Robust estimation of subspace coefficients. This package contains Matlab functions, which perform robust estimation of subspace coefficients in PCA, CCA and LDA methods.
Robust learning of subspace representations
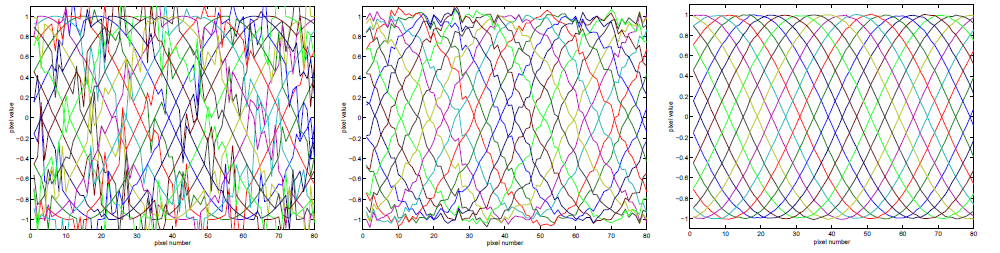
A reliable system for visual learning and recognition should enable a selective treatment of individual parts of input data and should successfully deal with noise and occlusions. These requirements are not satisfactorily met when visual learning is approached by appearance-based modeling of objects and scenes using the traditional PCA approach. In this work we extend the standard PCA approach to overcome these shortcomings. We first present a weighted version of PCA, which, unlike the standard approach, considers individual pixels and images selectively, depending on the corresponding weights. Then we propose a robust PCA method for obtaining a consistent subspace representation in the presence of outlying pixels in the training images. The method is based on the EM algorithm for estimation of principal subspaces in the presence of missing data. We demonstrate the efficiency of the proposed methods in a number of experiments. The figure below shows (the third image) how well the proposed method reconstructs the corrupted input signal (the first image) in comparison with the standard non robust approach (the second image).
Incremental and robust learning of subspace representations
To enable efficient operation of a cognitive agent in a real-world environment, visual learning has to be a continuous and robust process. In this work, we present a method for subspace learning, which takes these considerations into account. We present an incremental method, which sequentially updates the principal subspace considering weighted influence of individual images as well as individual pixels within an image. We further extend this approach to enable determination of consistencies in the input data and imputation of the inconsistent values using the previously acquired knowledge, resulting in a novel method for incremental, weighted, and robust subspace learning. We demonstrate the effectiveness of the proposed concept in several experiments on learning of object and background representations. The figure belows depicts the results of robust and adaptive background modelling. The second and the third row depict the reconstructed background. The reconstructions in the third row (the robust approach) do not include the foreground elements (cars and pedestrians passing by), as opposed to the images in the second row (the non-robust approach).

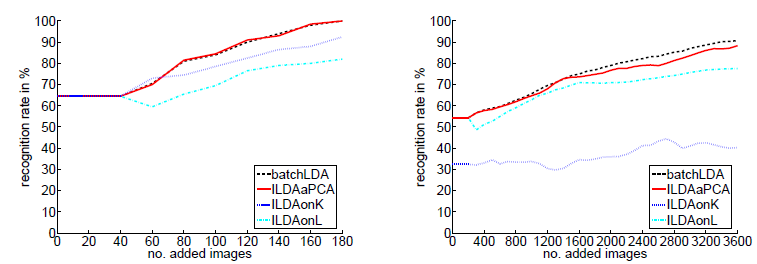
Incremental LDA learning
In this work we focus on incremental LDA learning which provides good classification results while it assures a compact data representation. In contrast to existing incremental LDA methods we additionally consider reconstructive information when incrementally building the LDA subspace. Hence, we get a more flexible representation that is capable to adapt to new data. Moreover, this allows to add new instances to existing classes as well as to add new classes. The experimental results show that the proposed approach outperforms other incremental LDA methods even approaching classification results obtained by batch learning. Some of these results are shown in the figure below, which demonstrate the good performance of the proposed approach (ILDAaPCA) in the cases of learning and recognition of faces (SDF database) and objects (ALOI database).