Researchers


Automated surface-anomaly detection using machine learning has become an interesting and promising area of research, with a very high and direct impact on the application domain of visual inspection. Deep-learning methods have become the most suitable approaches for this task. They allow the inspection system to learn to detect the surface anomaly by simply showing it a number of exemplar images.
Our research explores a segmentation-based deep-learning architectures that are designed for the detection and segmentation of surface anomalies and is applied to a specific domain of surface-crack detection. We developed a novel two-stage network architecture. The first stage implements a segmentation network that performs a pixel-wise localization of the surface defect, while the second stage, where binary-image classification is performed, includes an additional network that is built on top of the segmentation network and uses both the segmentation output as well as features of the segmentation net.
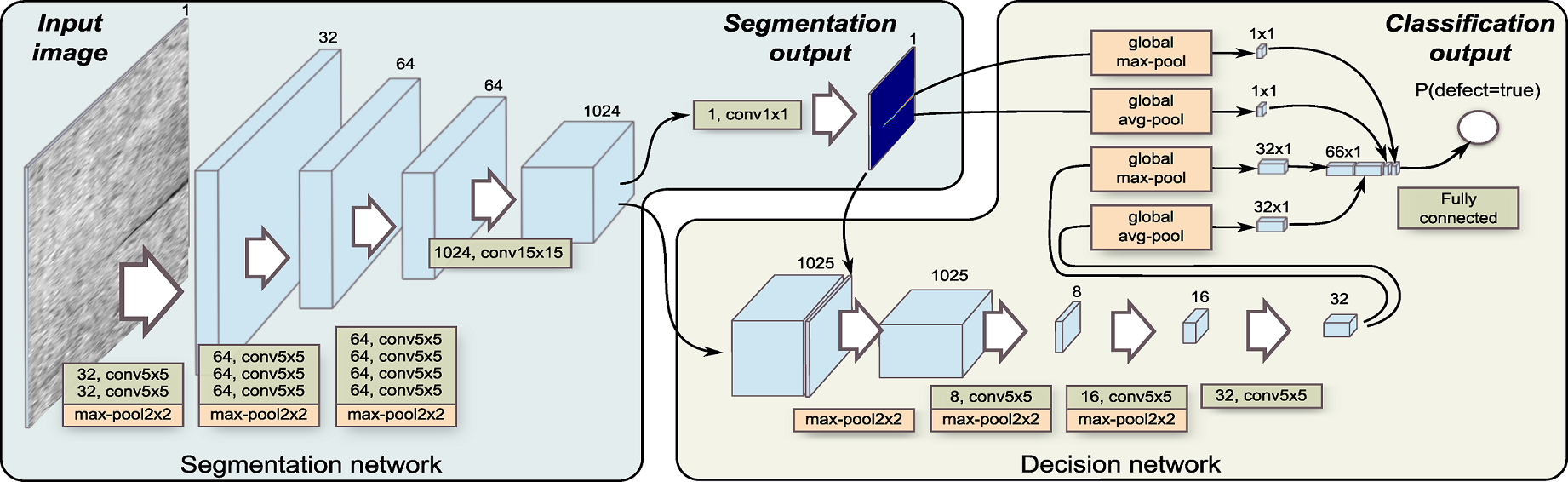
We explored three different implementations of the proposed architecture:
- one with our custom made segmentation network
- one with U-Net for segmentation
- one with DeepLab v3+ for segmentation
Additionally, we compared those models against a state-of-the-art commercial product. Experiments have been performed on a newly created dataset based on a real-world quality control case, which demonstrate that the proposed approach is able to learn on a small number of defected surfaces, using only approximately 25-30 defective training samples, instead of hundreds or thousands, which is usually the case in deep-learning applications. This makes the deep-learning method practical for use in industry where the number of available defective samples is limited.
This research is done in collaboration with our industry partner Kolektor Group d.o.o..
Code and datasets
We provide TensorFlow and PyTorch implementations of our model:
For benchmarking purpuses we provide two datasets created from real-world case of surface-defect detection:
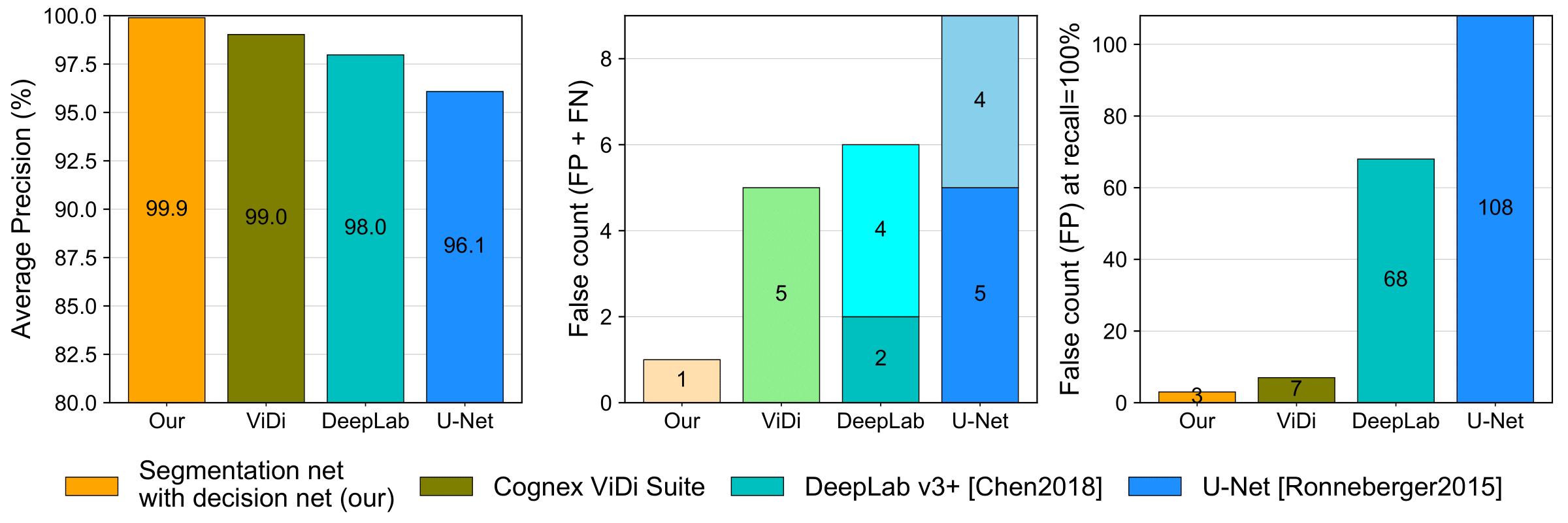
Results on KolektorSDD
The experiments on KolektorSDD demonstrated that our developed model achieves significantly better results than related methods with only one miss-classification, while the related methods achieve five or more miss-classifications.
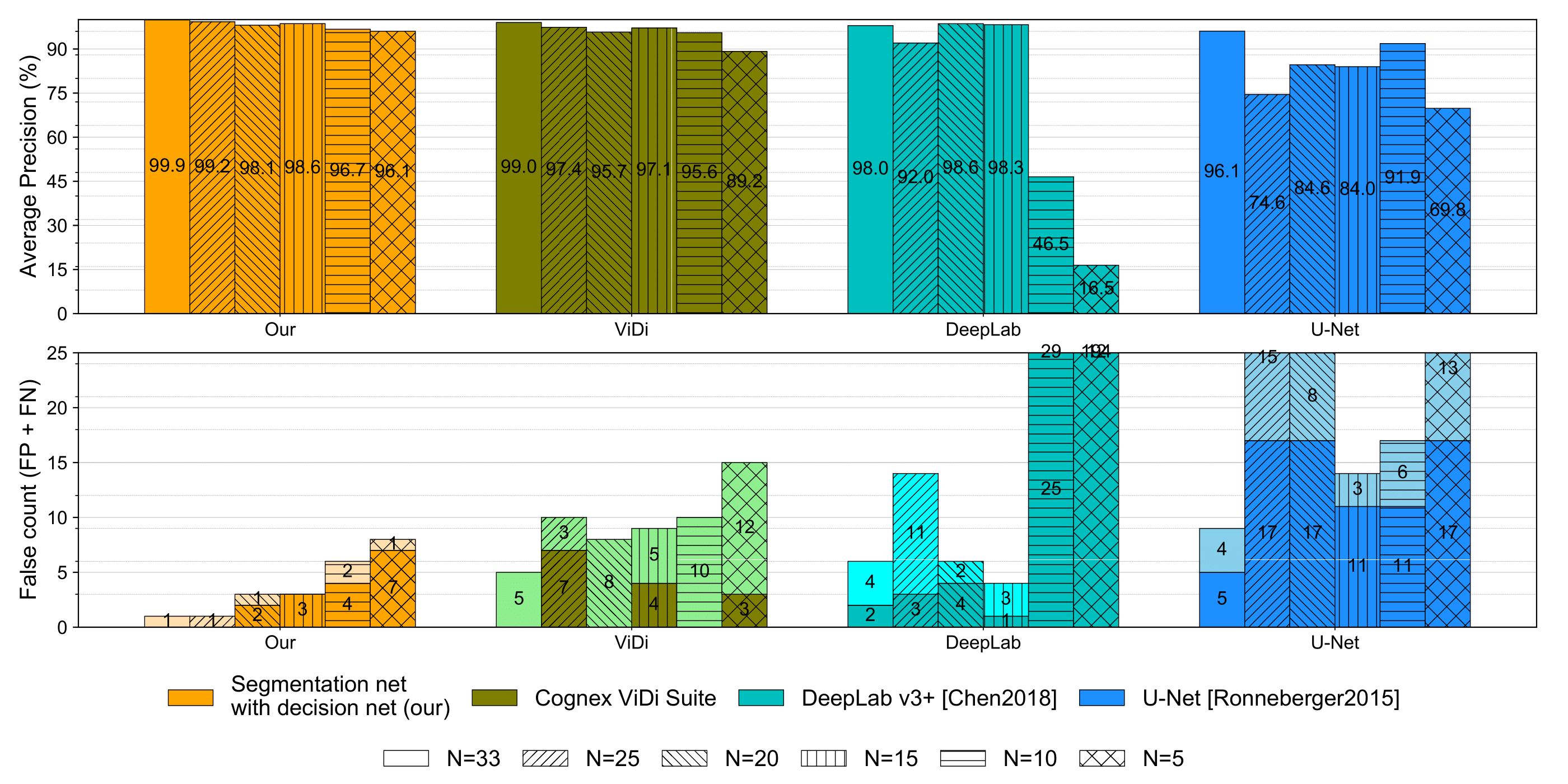
Sensitivity to the number of training samples
We also evaluated the effect of smaller training sample size.The number of positive training samples was reduced to effectively obtain the training size of 25, 20, 15, 10 and 5 samples for each fold, while the test set for each fold remained unchanged.
Some examples of detections with our developed architecture are shown below:
